My Data Science interviews
For more DS/ML interview questions, see this blog post.
Wondering how to efficiently prep for the upcoming DS phone interview? See this blog https://phdstatsphys.wordpress.com/2018/12/17/a-lean-approach-to-data-science-phone-interview/

What data science today was considered boring data processing back in the 1990s. WENUS, Weekly Estimated Net Usage Systems.
If you want to know what is a data scientist, check out this article on medium https://medium.com/@m.sugang/what-ive-learned-as-a-data-scientist-edb998ac11ec
This is a personal diary on my interview journey as I look for data scientist jobs. Buckle up and bookmark it since it is going to be a long one.
Some reminder to myself:
- Prepare and use the product if possible.
- Practice behavior questions the day before or on that day.
- Always be positive.
- Write thank-you letters to recruiters and interviewers if possible.
- Stick to things you know and be confident.
- For whiteboard coding, always run a test case with some edge case.
Some interview prep questions for ML/DS:
Background Questions:
1. Walk me through your resume (or some variant thereof)
2. Explain your past Ph.D./scientific work
3. Which techniques (that are relevant for Data Science) did you use in that scientific work?
4. What languages are you familiar with?
Technical Questions (In order of frequency of appearance):
1. Regression (the short answer here is to know everything) (Always)
– p-values, interpretation of coefficients, interaction coefficients
– know how to factor variables are dummy coded, coefficient interpretation
– linear regression assumptions: a linear relationship, the normality of residuals, no autocorrelation, no multicollinearity, homoscedasticity
– residual analysis, adding non-linear terms
– difference between L1 and L2 penalization, when you would use each one: L2 performs better in most scenarios and leads to small but never zero coefficients, L1 reduce the dimension of feature space.
– how to deal with highly correlated variables: PCA/regularization.
– walk me through how you would approach building a regression model to predict Y given you have data X
– how do you choose the right number of predictors
– logistic regression: how do you implement stochastic gradient descent for logistic regression with L2 regularization.
2. General predictive modeling (Always)
– train/test/validate sets, cross-validation, parameter selection, predictor selection, etc.
3. Random Forrest (Always)
– how a tree is grown
– purpose of increasing a forest
– purpose of selecting a subset of variables at each split
– variable importance
– knowing XGBoost vs random forest. How to split for the XGBoost?
4. Matrix Factorization (Rare)
– PCA, when do you use it? How are the components ordered? de-correlate features, reduce the dimension in the high dimension/sparse data. Ordered by the variance.
– I’ve never been asked about factor analysis, but it is great to know and makes other related questions easier
5. K-means clustering (often)
– What is the loss function? When does it converge? RMSE
– know the algorithm iteration steps
– how do you choose the right number of clusters? domain knowledge or use DBSCAN.
– is the optimization convex? The loss function is convex.
6. Standard Stats (Often)
– t-test assumptions: sample from the normal distribution, sample independence, homoscedasticity
– z-scores
– chi-square test: the residual is normally distributed, needs a large number of data for the approximation of chi-squared distribution to hold, independence.
– know covariance and correlation equations
– when splitting the data by random users, you need to take into consideration that some users may interact with each other. For example, if you are testing a new pricing algorithm in Uber, you should not split the users in the same city/neighborhood. If you are testing a new ranking algorithm for encouraging users to answer questions, then you should not let expose the same questions to the different algorithms. After a lot of high-quality answers, users are less likely to add their answer.
7. Time Series (Rare)
– ARIMA model, PACF vs ACF, how to choose the AR and MA terms.
– unit root test, normality test.
I’ve also never been asked any SQL queries yet in interviews yet.
The interview experience:
I going to write about my interview experience in a chronical order with good and not-so-good things.
Phone interview/JPMorgan/Machine learning Engineer intern/rejected
What is the overfitting? How to overcome it?
If you have some data that are partially labeled, will that improve your supervised learning model?
What is bias-variance trade-off?
Write out the loss function for logistic regression. How to add L1/L2 regularization?
How to apply the Stochastic Gradient Descent (SGD) to logistic regression?
Given a list that contains some animals like [“bear”, “bird”, “bird”, “chicken”, “mouse”, “mouse”], find out the animal that appears most frequently in the list.
Phone interview/Hidimensional/a referral firm/rejected
What is the global cost function for the random forest? Some more questions about basic ML algorithms like Logistic regression.
Good feedback about my interview skills.
Website: https://hidimensional.com/
Zoom interview/Insight data science/A data science boot-camp for Ph.D./Offer
Tell me about your Ph.D. What are your conclusions?
Prepare a small ML project. Get asked questions about why do you choose this algorithm vs. another.
https://www.insightdatascience.com/
If more people are interested in my experience, I will write it on another blog.
Onsite interview/Wayfair/Senior data scientist/rejected
The onsite interview consists of 4 interviews. First two are technical, the third one is to introduce you to the team structure, the fourth one is also technical. They focus a lot on applying ML algorithms to the business case, expect 2-3 interviewers to ask about how to use ML in a business case.
All my interviewers got changed last minute and some other last minute changes. Two interviewers prepared the same coding question.
Coding: Suppose you have a basket of things like 5 sofas, 6 beds, and 7 lamps {“sofa”: 5, “bed”: 6, “lamp”:7}, write a function to randomly pick an object.
Business case: How do you come up with an algorithm to predict the auction price of an advertisement for a blue sofa on google search? What metrics could you use to measure if the new algorithm improved? What if there are only a few data points for some new items so that you ML algorithm does not have enough data?
Hackerank/Goldman Sach/Decision data scientist/rejected
All multiple choice math questions.
- Calculate the volume expanded by y = x^2 when you rotate the curve around the y-axis.
- Calculate the length of the curve y = x^2 +1 from [0,1].
- The limit of sqrt(6+sqrt(6+sqrt(6+…..))). sqrt means squared root.
- Some combinatorics question. Suppose you have three open-ended strings. Each time you choose two open ends to knot them together. After three rounds, what is the probability that the end result is a circular ring?
Skype interview/Edgestream/Research scientist/Rejected
You are asked to present your Ph.D. work in a 20-minute presentation over screen share on skype. Then, you are given a chance to ask them questions. No technical questions.
Phone interview/Gamalon/Data Scientist/Rejected
Introduce you to the role a little bit. Machine learning prototype work + customer facing. 1. What is it that you wish to learn for the next two years? 2. Tell me about yourself.
Phone interview/JPMorgan/Roar team data scientist/Rejected
Just an hour-long interview asking about your background, what you have done in the past and what is your knowledge level on cs/python/tensorflow/generator. No technical questions. One brain-teaser: How many times does 2 appear in the sequence of 1 to 1 million?
Phone interview/Quora/Data Scientist/proceed to onsite interview
Ask about how do you rank the questions&answers of Quora’s feed. How do you use machine learning to build a model to do that? What is recall vs. precision? After you develop the model, how do you use A/B testing to show that your algorithms work better? How to do power analysis? What is power? A comprehensive test of ML and A/B testing.
Onsite interview/Quora/Data Scientist/rejected
The onsite starts from 10:15 am to 3:30 pm. The first 15 mins is an office tour.
The first interview is data practical, which consists of two questions. The first one is a question about data manipulation and the second one is about doing an A/B test on the data.
The second interview is about A/B tests and product intuition. Asked about assumptions behind different tests. What if the data is not normally distributed? Why the data is normally distributed? How do you design an algorithm to decide when you should send out the email? Think about the features you are gonna use and watch out for correlated variables. How do you deal with correlated variables? Regularization vs. tree-based models.
The lunch is mostly about selling themselves to you, letting you ask questions about the team and the company.
The third interview is about different kinds of metrics and how do you do the random splitting for A/B testing. There are a lot of detailed questions about why use this metric, why not using this metric, and if the approach is problematic, how do you solve it.
The fourth interview is a coding problem. Given a large integer stored as a string, how do you come up with a function to do multiplication?
The fifth interview is behavior based. What is the biggest mistake you have made and what have you learned from it? Tell me about a time you break a rule. Tell me about one of the projects you have worked on.
After the interview, I felt that I did not do so well and I am not a good fit for the position. If you have an extensive background in stats, then you should consider Quora’s data science team, which is separate from the ML team.
I got rejected within two business days. I love the product and the team, they are moving really fast in the process, which I really appreciate. The entire onsite interview process is rather seamless.
Technical Assessment + phone screen with HR/CarMax/Senior data scientist/No response after two months.
The technical assessment has nothing related to data science. Most of the questions are just reading graphs and some percentage calculations under a time limit. I did not get to finish all the questions. I felt that the questions are appropriate for a business analyst.
The phone screen is just a casual conversation with HR about the company and the team. I heard that the next round is doing a business case problem on the phone, which seems to me that they are looking for a business analyst instead of a typical data scientist. My friend told me that there is no ML/Stats/Coding question at all.
Some more prep questions from Glassdoor:
1. How to choose two ranking algorithms?
from email or session time, upvote, follow, request an answer, session time, answer a question.
2. What do you want to improve about Quora? What features do you want to include? What features do you like about Quora?
3. There are X answers to a certain question on Quora. How do you create a model that takes user viewing history to rank the questions? How computationally intensive is this model?”
4. You’re drawing from a random variable that is normally distributed X ~ N(0,1), once per day. What is the expected number of days that it takes to draw a value that’s higher than 2?
5. How would you improve the “Related Questions” suggestion process?
6. Write a function to return the best split for a decision tree regressor using the L2 loss.
7. Why do you want to join Quora?
8. Pandas.
9. growth analysis
10. Print the element of a matrix in a zig-zag manner.
Phone screen+data challenge/Watchtower.ai/first data scientist/proceed to onsite interview
I got referred by a friend. The phone screen is mainly talking about your background and what you are looking for in a data science position. They (the two founders) talked about the company they are trying to build. They asked me if I have time to do a data challenge, and even offered me an alternative or an alternative project if I did not have the time. The told me that they are looking for the first data scientist right now.
I tried to do the project over the weekends and send them my Github account with a simple slide on Monday. Then, I talked with them over zoom about the project and got invited to their office in SF. I could provide my Github repo later if anyone is interested.
The company is relatively small so that everything is moving really fast, which is something I really appreciate and love.
Onsite/watchtower.ai/data scientist/Rejected
The interview starts at 11:59 am. The entire interview is about implementing the kmeans algorithm and apply it to an image color vector quantization. See more details here on another blog. You will first talk about kmeans, how it works and write it in Python for the first 1.5 hrs. Then, you will go to have lunch with the team. Then, you will continue to implement the kmeans algorithm and apply it to an image. I did not get to finish it in time since I did not know about the proper way to deal with initialization and sometimes a bad initialization leads to all data to be assigned to one single cluster. I got some more time to work on it after the interview. At the end of the onsite interview, you got some time to ask them some more questions and they will ask you some more questions.
I have written about Kmeans and how I implemented it here.
After about 10 days (over the Thanksgiving weekend), they give me a call on about their concerns about both my skills and visa status. The phone call was really nice since they point out where I could improve on. I will need to improve on writing code faster and wiring code that is production ready.
Phone Screen + data challenge/Upstart/data scientist/Rejected
The HR screen was mainly about the team at Upstart and the work they do. Then, I talked about my background and where I am strong at. They really care about whether you have written a lot of code before since the HR asked me how many lines of code I have written before.
After the phone screen with the HR, I was quickly given a data challenge over the weekend. The problem was a simple survival analysis with Kaplan-Meier estimator. But I made two mistakes and did not get to proceed with the interview.
I will write about the lessons I learned from this interview in the future.
Phone screen/Vinya intelligence/data scientist/Rejected.
I was first sent some materials to look at before the phone screen. The phone screen was with the CEO. He talks in great detail about the Vinya intelligence and then I talked about my background, asked a lot of questions about the company and how do they expect the growth to be.
I am currently waiting for them to schedule the onsite interview since Christmas is coming.
After Christmas, I sent a follow-up email but was told that there were problems with their funding and they were not hiring right now.
Phone screen/Root insurance/data scientist/Rejected
First, I talked about the thing I know about Root insurance and the VP will talk about in more detail about Root insurance. Then, I asked some questions about the team, projects and etc.
Then it moves on to technical questions, which is totally surprising to me since the HR did not mention anything about technical questions. But I felt that I should know that since I am scheduled for a 1hr phone call with the VP.
He first asked me about the central limit theorem and how it can be useful. How to estimate confidence intervals and how to use bootstrapping for estimation.
Then, he asks about how to derive the analytical solution for the linear regression from the L2 loss to the final solution. Then we move on to talk about why Logistic regression vs Linear regression, what is the loss function? Why use Logistic regression for 0/1 labeled data. Lastly, we talked about what would you do if the data is imbalanced? What kind of metrics should you use? I also have written about this topic recently on my blog.
The next step is to do the data challenge, and I am still waiting for a response from them.
I got the rejection letter about a week later.
An important lesson I learned from this phone interview was to refresh the things you think you know before every interview. I will have a checklist/blog on this in the near future.
Phone screen/CVS supply chain team/data scientist/Rejected
A friend at the Insight Data Science Bootcamp referred me this job. The phone interview was conducted by two people. I was pretty nervous and stuttering during the entire process, especially in the beginning. Both of the interviewers have been through the Insight data science program as me and they have been trying to calm me down.
The question was about how to design a program for the elevator. How do you design the interface for the buttons in the building and how to design the buttons in the elevator? How do you store a sequence of requests from the building? How do you determine the sequence of actions based on the requests available now? What kind of object in Python should you use for the interface and main program? Python class.
You will need to explain your logic in an abstract way. No whiteboard coding problem.
Phone screen/Wayfair/data scientist Ph.D./Rejected
Applied to Wayfair again after 6 months. I got a phone interview a week after the online application. The interviewer was late for 10 mins due to some confusion.
He first introduces himself as someone from the Direct Mail team and the Data Science team structure in Wayfair. Then, I introduce myself as per usual.
Then he went on to ask me why does Wayfair want to match two or more different devices to the same person (a more complete picture of the user). Then, he asked me to give an example of the usage (better ad tracking and marketing). This is a brief introduction on the topic if you are not familiar with it. https://clearcode.cc/blog/deterministic-probabilistic-matching/
Later we move on to the more technical part of the interview. He asked me about what features and approach will I use to solve that problem. I proposed to get some labeled data first by considering whether they have opened the same email from Wayfair, whether they have login the same account in different computers and etc. After obtaining some labeled data, I discussed some device attributes and user behaviors that can be used in the algorithm. These are the two articles that discussed the attributes and process in cross-device matching in more detail. If you are in a hurry, these two articles are all you need.
https://blogs.gartner.com/martin-kihn/how-cross-device-identity-matching-works-part-1/
https://blogs.gartner.com/martin-kihn/how-cross-device-identity-matching-works-part-2/
Then, I propose to use the DBSCAN algorithm (unsupervised learning method) to determine if the devices belong to the same user. I will use the labeled data to measure the performance of DBSCAN and tune the two major hyper-parameter minimum number of points and radius.
For more on DBSCAN, see here https://towardsdatascience.com/how-dbscan-works-and-why-should-i-use-it-443b4a191c80.
Then he went on to ask me how do we apply supervised machine learning on this problem. What is your target value? I said that I would assume that each user is a class, which can lead to millions of classes for Wayfair. He suggested that we reduce the problem to whether the two devices belong to the same person. The problem is then transformed into a binary classification problem. I did not get that point even until now as to how to train the model with the data.
In the end, I asked some questions about team growth and career development in Wayfair. The interview was kind of rushed in the end due to the fact that he is late for 10 mins.
Some preparation questions from Glassdoor:
Introduce yourself first.
Describe a project that you most proud of?
Questions:
1. How would you evaluate the effectiveness of various ads?
2.(most frequent in glassdoor) Match users using different devices to browse items, the devices are phones or laptops.
3. recommend goods to the customer
4. Given the available data, walk me through how you would value a marketing campaign from a data science perspective.
5. Wayfair decides to not offer phone customer service to half of their online customers. Why would Wayfair decide to do that?
6. Match furniture in a scene given query pictures plus computer vision basics.
7. Data science business case (i.e. click through, customer retention, etc)
8. What are the potential weaknesses of that pricing strategy?
9.sale tag case
10. How do you quantify the overall effect of SALES flag on the Wayfair website? What model to use?
11. Some question about website data analysis, a question on how to evaluate the influence of sale tags on the website.
what’s the difference between random forest and gradient boosting?
The dependent and independent variables. Which algorithms? Why this algorithm? Is there any unbalanced data? What kind of metrics do you use to evaluate the algorithm?
What kind of job will make you excited to go to every morning?
Phone screen/Jasmine22/second data scientist/Rejected
The position was referred by a headhunter in HK. The phone screen was conducted over Google meetings. The interviewer was several minutes late. He just said “introduce yourself” after he got into the Google meeting with no introduction of himself and the team nor did he apologized for his delay. It appeared very rude and disrespectful to me as a candidate. Other than that, I believed that he put the laptop on his legs and kept shaking his leg during the interview. It was just the worst and most disrespectful interview I have ever had so far. This is the end of my complaint.
He started the interview with “introduce yourself”(first red flag). After I talked about my experiences, he went on to ask about one of my recent projects with word2vec. I tried to explain what word2vec is and how I obtained my data, but he seemed to be confused a bit. Then, he went on to ask me about any supervised and unsupervised machine learning model I know. I tried to explain some of the algorithms but he suddenly interrupts me when I was talking about Kmeans (second red flag). He then asks me how do you make sense of the clusters. I tried to explain to him that kmeans was only optimizing on the within-cluster sum-of-squares and you have to make sense of the cluster formation afterward. He seems to be confused about what I am talking about so that I asked him for some background information on this question. He told me that he is doing something related to clustering companies into different growth potential (big company but slow growth or small company but high growth etc ). After explaining a little bit more about how kmeans works, I came to the conclusion that he had no idea or understanding of how kmeans works as that company’s first data scientist(another red flag). I offered him a solution that is to look into the profile of the company after the clustering process. I then asked him about company growth, possible projects, team structure, etc. Another red flag here was that the company was trying to tackle some supply chain problem and refinancing problem for the small to medium company at the same time.
I got the rejection after a few days saying that I lacked the work experience, which they know with me coming into the interview. But I totally understand that if they have found a candidate with more work experience.
Phone screen + data challenge/ RiskIQ/data scientist (research oriented)/Rejected
I got this interview from the Insight data science. The first call was with the VP of engineering. It was a fun interview. I got to ask many questions regarding the role and the company. I also introduce me about my experience and the kind of problems I have been solving and solved. The call ended early with me moving the next round of interview- the data challenge.
The situation goes downhill from there. When they sent over the data challenge after my reminder email, my name was wrongly spelled. I thought to myself, it could happen to anyone including me with that damned autocorrect. But this is probably the first red flag.
The second red flag was with the data challenge. The data they sent over needs some degree of cleaning, which is quite normal. They want to know if you could and know how to deal with them. But a large part of the data is hashed and the questions are too open-ended. I have to emphasize that the role itself is a bit of research-oriented so that I understand the nature of the open-ended questions. But the goal of the data analysis is so unclear as to you do not know where should you start to explore them at all.
These are the questions that were asked:
* what does the distribution of dependent requests across hosts look like? What other basic statistics might be interesting to describe this data?
* can you classify hosts into reasonable “types” based on these features? Conceivably, www.google.com will look different from www.nytimes.com, but perhaps www.google.com and www.bing.com are similar?
The HR went into radio-silence for two weeks after I sent in the data challenge and sent me a standard rejection letter. When I asked for some feedback from it, they did not reply with anything. That is when I raised the suspicion and reflect on the entire interview process and write this down.
Leave a comment below if you are interested to know what the data challenge is. I can share my GitHub repo with you.
two Phone interviews+ data challenge/Peloton/product analyst/Just submitted data challenge
I referred by a friend to this position. Applied in April and got a reply in early May. The first call was a casual phone call with HR talking about the role, the company, the team, and the next steps. The HR was really nice mentioning about their really awesome policy on visa sponsorship and green card. That was a really pleasant call for a long while.
The next step was with a senior analyst on the team. She was a really nice person and a pleasure to talk to. She is very polite, respectful and patient with my questions regarding the team. the projects and etc. The interview started with her introducing the team, the company, the eco-system they are trying to build. She then gave me some context on the product and asks me some metrics I will measure to understand the user-engagement. The second question was about how to use user data to understand if the user was using the heart rate monitor or is the heart rate monitor working at all.
Then, I got to ask questions on the team and the onboarding process. The on-boarding process is two projects: one was getting you familiar with the data pipeline they have, the second was a more open-ended research problem. (I ask onboarding projects because it is a good gauge on the work they expect you to do and if they are really hiring.)
The next step is a data challenge with AB testing problem. I also have a point of contact if any questions arise. I had a question on the experiment time on Saturday Night at 11pm, and the contact replied within 10 mins. That is just amazing communication!
Now I am waiting for the verdict for my data challenge. I have put my results on my GitHub here https://github.com/edwardcooper/peloton.







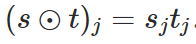
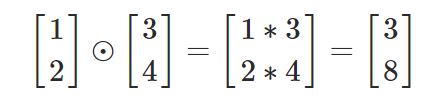
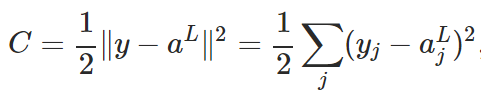
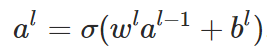
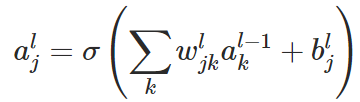
 is defined as
is defined as
 is defined as
is defined as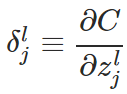

 , thus we have
, thus we have .
. only depends on
only depends on  , as is defined in the equation below
, as is defined in the equation below

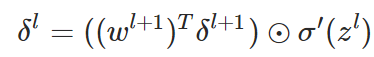
 .
. .
.
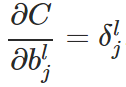

 from the definition that
from the definition that  .
. .
.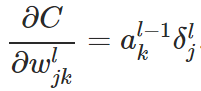
 .
.