For the unsupervised learning algorithm, the Kmeans algorithm is one of the most iconic unsupervised learning methods. In this blog, I will try to explain the Kmeans algorithm and how to implement it in Python.
- The first step is to generate some random data points to be the cluster centers based on the number of clusters to separate the data into.
- The second step is to assign data points to different clusters based on a distance metric. (You could choose the Euclidean distance, Manhattan distance, Mahalanobis distance, or cosine similarity based on the detail of the project. I will talk about the different distance/similarity metrics in a future blog.)
- The third step is to calculate the new cluster center based on the new cluster assignment. The most simple way to calculate the new cluster center is by taking the mean of the data in the new clusters.
- Iterate step 2 and 3 until the changes in the center of the clusters are smaller than a specific value.
The GIF below summarized all the steps stated above._
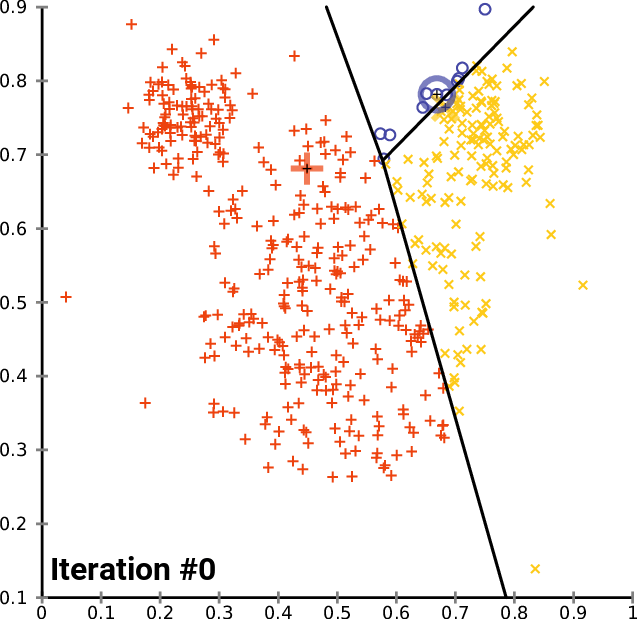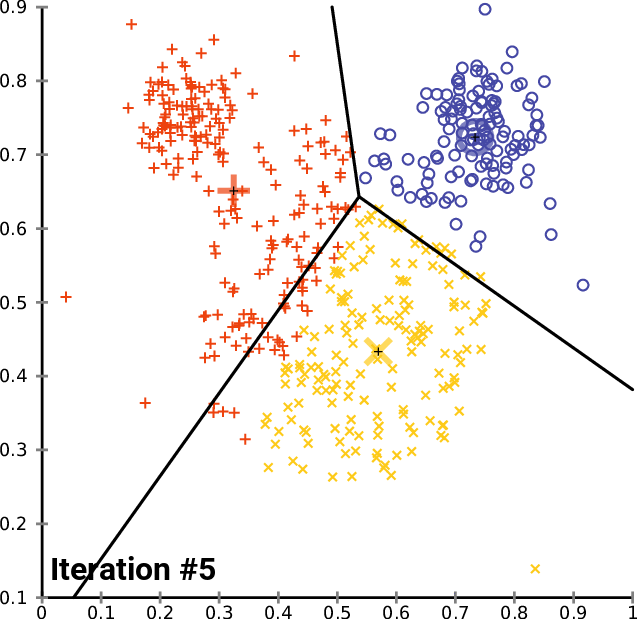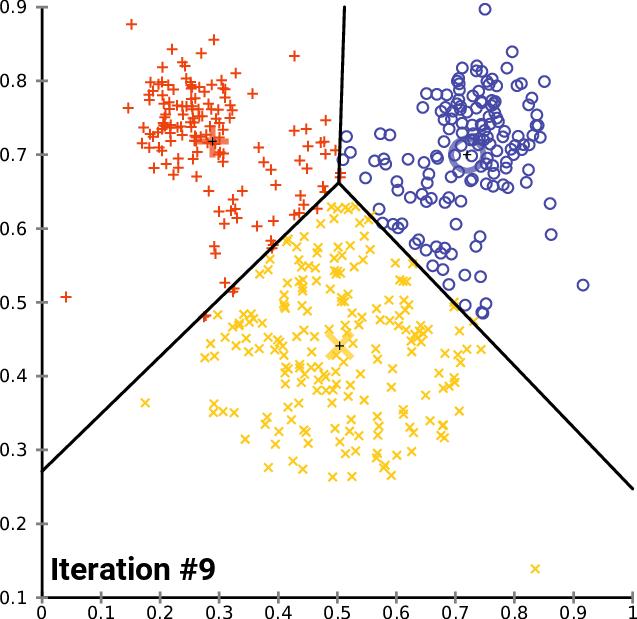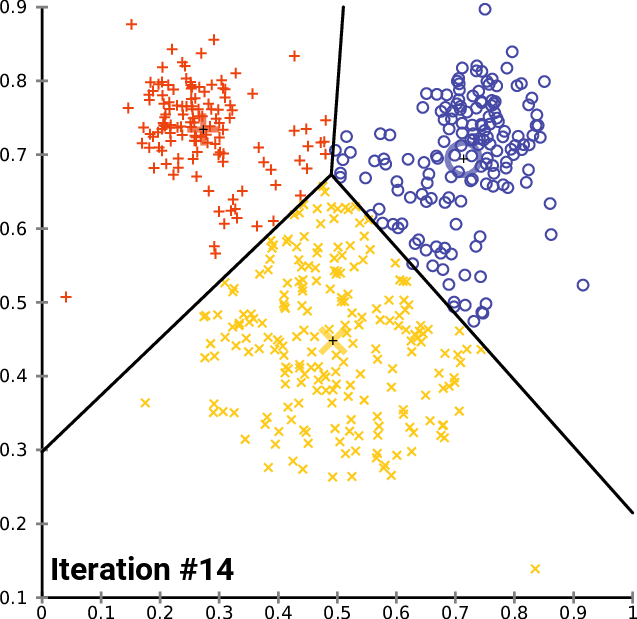
image from Wikipedia https://en.wikipedia.org/wiki/K-means_clustering#/media/File:K-means_convergence.gif
Side note:
- Because of the random initial cluster centers, the Kmeans algorithm will lead to a slightly different result. Then, it is customary to run Kmeans several times to determine if the algorithm converges to a similar solution.
- Due to the fact that the Kmeans algorithms use some type of distance metric, it is crucial to transforming the data to have zero mean and unit variance or in the {0,1] range.
- The final clusters can be very sensitive to the selection of initial centroids and the fact that the algorithm can produce empty clusters, which can produce some expected behavior. There is a specialized algorithm called kmeans++ optimized for the initialization of the cluster centers.
- The final selection of the Kmeans algorithm and the number of clusters in Kmeans can be done by choosing the algorithm that has the lowest within-cluster-variance and many other metrics that can be chosen from. See this blog if you want to know more.
This jupyter notebook in my Github describes all the code and the details of how I implemented the Kmeans and apply it to an image to do color vector quantization.
I have also refactored all the code above into a class in python with the fit, predict, transform method as implemented in sklearn and some other helper functions for ease of use. It is also in my GitHub. I have also added some examples on how to use the Kmeans algorithm I implemented.
Let me know if you have any questions.
If you have just started to learn python, this python tutorial by Corey is the most awesome I have ever seen. He explains everything so well and covers a lot of practical topics.

{kind=link}
One comment